

Bedingungen:
Hardware: Dual AMD Opteron 6376, 32 x 2.3 GHz (Turbo Core aus)
BS: Windows 7 Pro 64-Bit
GUI: keine
Settings: Alle Engines default settings
Large Tables: keine
Stellung: Grundstellung
Rechenzeit: 20 Sekunden
UCI Kommandos:
setoption name threads value 1 (bis 32)
go movetime 20000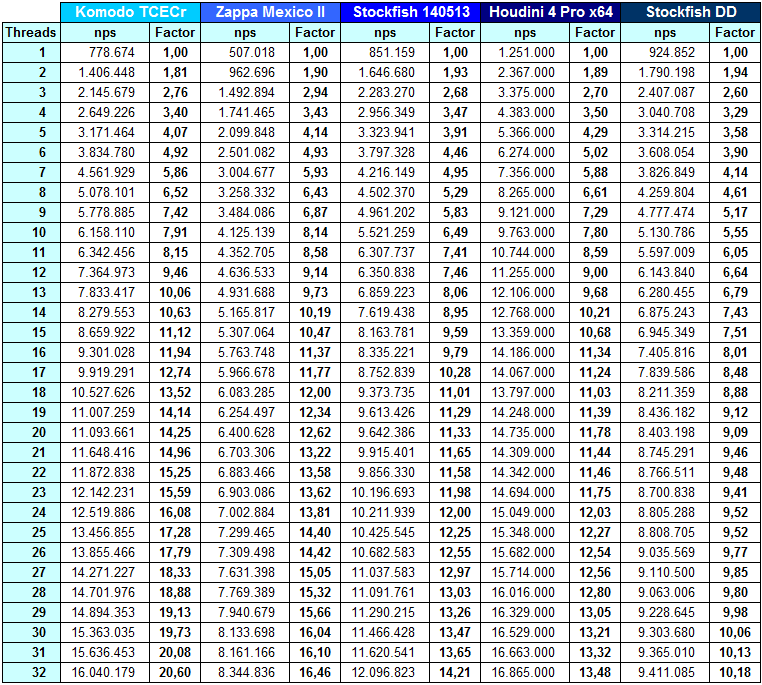
Komodo TCECr (11,94 - 20,60 = 73%)
Zappa Mexico II (11,37 - 16,46 = 45%)
Stockfish 140513 ( 9,79 - 14,21 = 45%)
Stockfish DD ( 8,01 - 10,18 = 27%)
Houdini 4 Pro (11,34 - 13,48 = 19%)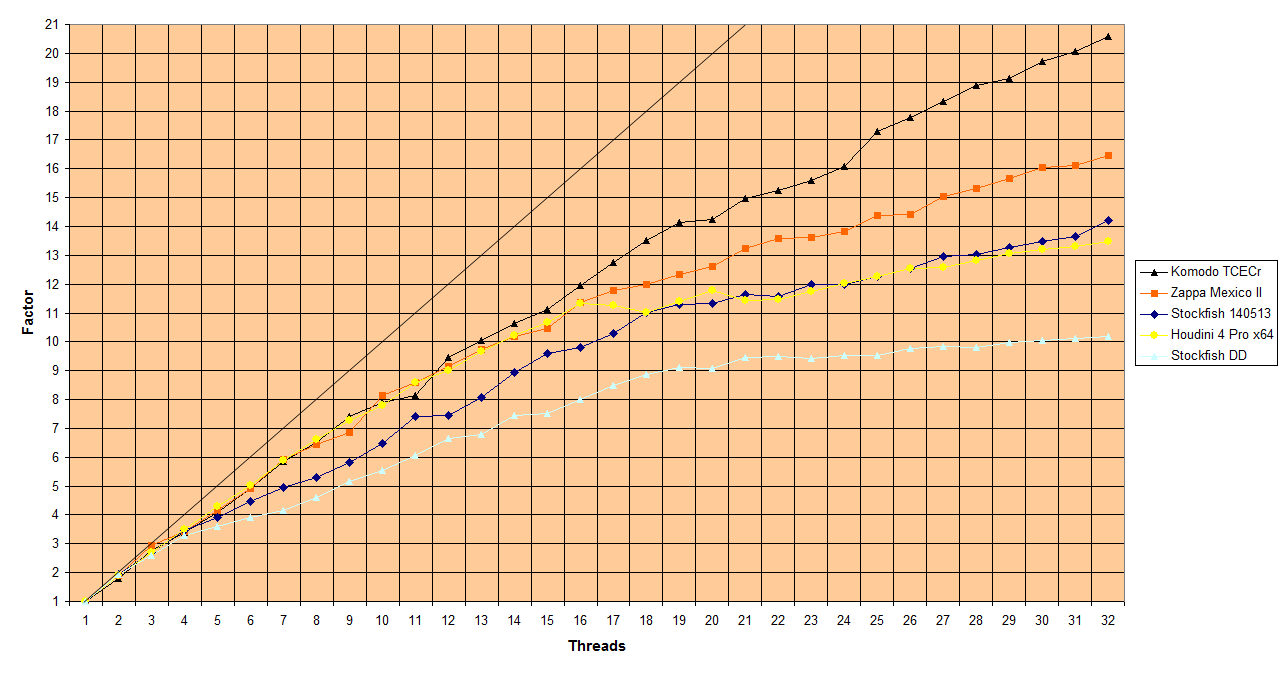 By Thomas Plaschke
Date 2014-05-17 10:49
By Thomas Plaschke
Date 2014-05-17 10:49
 By Ingo B.
Date 2014-05-17 10:56
By Ingo B.
Date 2014-05-17 10:56
 )
By ?
Date 2014-05-17 21:46
By Ingo B.
Date 2014-05-18 08:39
By Ingo B.
Date 2014-05-18 09:15
By Ingo B.
Date 2014-05-18 11:11
) in der Praxis taugen Knoten aber nur für denjenigen der den Sourcecode kennt und sind ansonsten irrelevant (insbesondere im MP Betrieb).
By Thomas Plaschke
Date 2014-05-18 13:20
)
By ?
Date 2014-05-17 21:46
By Ingo B.
Date 2014-05-18 08:39
By Ingo B.
Date 2014-05-18 09:15
By Ingo B.
Date 2014-05-18 11:11
) in der Praxis taugen Knoten aber nur für denjenigen der den Sourcecode kennt und sind ansonsten irrelevant (insbesondere im MP Betrieb).
By Thomas Plaschke
Date 2014-05-18 13:20
> Unterschiedliche Knotenzahlen sind mE nur zum Vergleich verschiedener Versionen einer Engine aussagekräftig
By ?
Date 2014-05-19 08:41
Stockfish DD wäre auch durch einen anderen Suchansatz zu erklären (ab einer bestimmten Core-Anzahl weniger selektiv). Ich vermute aber, dass Stockfish140513 schlicht stärker selektiert.Togas Knotenleistung und Tiefe bei 16 Cores kaum besser waren als auf meinem 4 Core-PC.> Als Nicht-Fachmann ist mir bspw. aufgefallen, dass die Threads untereinander über Datenstrukturen kommunizieren, die zeitweise für andere Threads gegen lesen oder schreiben gesperrt werden. Dadurch scheint mancher Engine eine Menge Sand ins Getriebe zu geraten. Im TCEC ist mir aufgefallen, dass Togas Knotenleistung und Tiefe bei 16 Cores kaum besser waren als auf meinem 4 Core-PC.
 By Thomas Plaschke
Date 2014-05-19 20:03
By Ingo B.
Date 2014-05-18 12:46
By Ingo B.
Date 2014-05-18 12:45
By Thomas Plaschke
Date 2014-05-19 20:03
By Ingo B.
Date 2014-05-18 12:46
By Ingo B.
Date 2014-05-18 12:45
 By Ingo B.
Date 2014-05-18 18:41
), probier ich's auch nochmal, obwohl es Roland eigentlich schon gut genug auf den Punkt gebracht hat.
By Ingo B.
Date 2014-05-18 18:41
), probier ich's auch nochmal, obwohl es Roland eigentlich schon gut genug auf den Punkt gebracht hat.
> Kn/s sind ungeeignet um die Qualität der Implementierung der parallelen Suche zu bewerten.
> Aber was da so im Einzelnen passiert, wenn eine Engine bei Kernverdopplung nur 20% nps gewinnt, würde mich doch interessieren.
> Es ist trivial eine goofy Suche zu programmieren die perfekt skaliert bezüglich kn/s. Die Effizienz dieser Suche wäre aber freilich ungenügend.
>Sicher hat Dr. Hyatt sehr viel Erfahrung, aber er hält auch sehr an 'alten' Erkenntnissen fest. Frei nach dem Motto: was nicht sein kann, darf nicht sein.
> denn die Suche liefert mit threads > 1 möglicherweise bessere Qualität
> Tiefe 18 ist natürlich schon 'ne Hausnummer.
Motor Punkte
1: Stockfish_14051914_c2 151,0/298
2: Stockfish_14051914_c1 147,0/298> Vielleicht mache ich hier mal einen Test mit 1 zu 8 Kernen
Rank Name Elo + - games score oppo. draws
1 SF-T8 6 9 9 1000 52% -6 61%
2 SF-T1 -6 9 9 1000 48% 6 61% Finished game 1000 (SF-T1 vs SF-T8): 1/2-1/2 {Draw by 3-fold repetition}
Score of SF-T8 vs SF-T1: 217 - 178 - 605 [0.519] 1000
ELO difference: 14
Finished match1: Stockfish_14051914_c1 509,5/1000
2: Stockfish_14051914_c2 490,5/1000 1: Stockfish_14051914_c1 516,5/1000
2: Stockfish_14051914_c4 483,5/1000 >Da die traversierende Baumsuche nunmal inhärente serielle Merkmale aufweist, ist deren Parallelisierung niemals trivial und auf Schach bezogen heißt das, dass man versuchen muss a) möglichst wenig Arbeit doppelt zu machen und b) Ergebnisse möglichst unmittelbar in die Suche einfließen zu lassen, um nicht an schon "veralteten" Stellungen herumzurechnen.
Powered by mwForum 2.29.3 © 1999-2014 Markus Wichitill


 CSS-Shop
CSS-Shop