<code>
Bedingungen: Hardware: Dual AMD Opteron 6376, 32 x 2.3 GHz (Turbo Core aus)
BS: Windows 7 Pro 64-Bit
GUI: keine
Settings: Alle Engines default settings
Large Tables: keine
Stellung: Grundstellung
Rechenzeit: 20 Sekunden
UCI Kommandos:setoption name threads value 1 (bis 32)
go movetime 20000</code>
Die Tests wurden im Konsolenmodus ausgeführt.
Das bedeutet z. B. unter Windows die .exe auszuführen und dann die UCI Kommandos einzugeben.
Hier die Werte der einzelnen Engines von 1 bis 32 Threads aus der Grundstellung heraus mit 20 Sekunden Rechenzeit.
nps = nodes per second = Knoten pro Sekunde
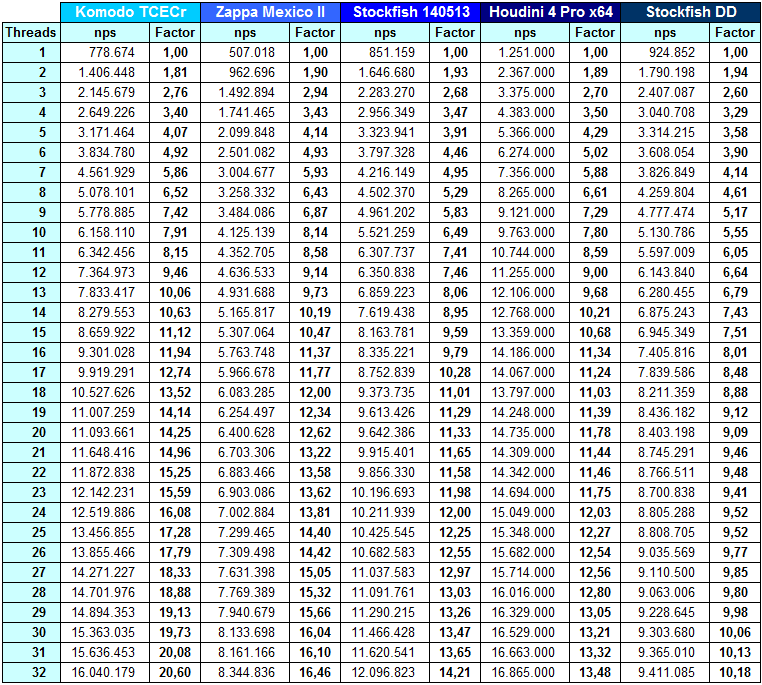
Komodo, Houdini und Zappa liegen bis 16 Threads fast gleichauf (Faktor 11,94 - 11,37 - 11,34). Stockfish DD und auch die neueste Stockfish Version fallen hier bereits ein wenig ab.
Komodo skaliert auch jenseits der 16 Threads noch ausgezeichnet. Auch bei Zappa zeigt sich eine gute SMP-Implementierung.
Bei Houdini und Stockfish DD ist nach 16 Threads keine große Steigerung mehr erkennbar, während bei der aktuellen Stockfish Version eine positive Entwicklung in diesem Bereich zu sehen ist.
Steigerung von 16 auf 32 Threads:<code>
Komodo TCECr (11,94 - 20,60 =
73%)
Zappa Mexico II (11,37 - 16,46 =
45%)
Stockfish 140513 ( 9,79 - 14,21 =
45%)
Stockfish DD ( 8,01 - 10,18 =
27%)
Houdini 4 Pro (11,34 - 13,48 =
19%)</code>
Hier noch die graphische Aufbereitung:
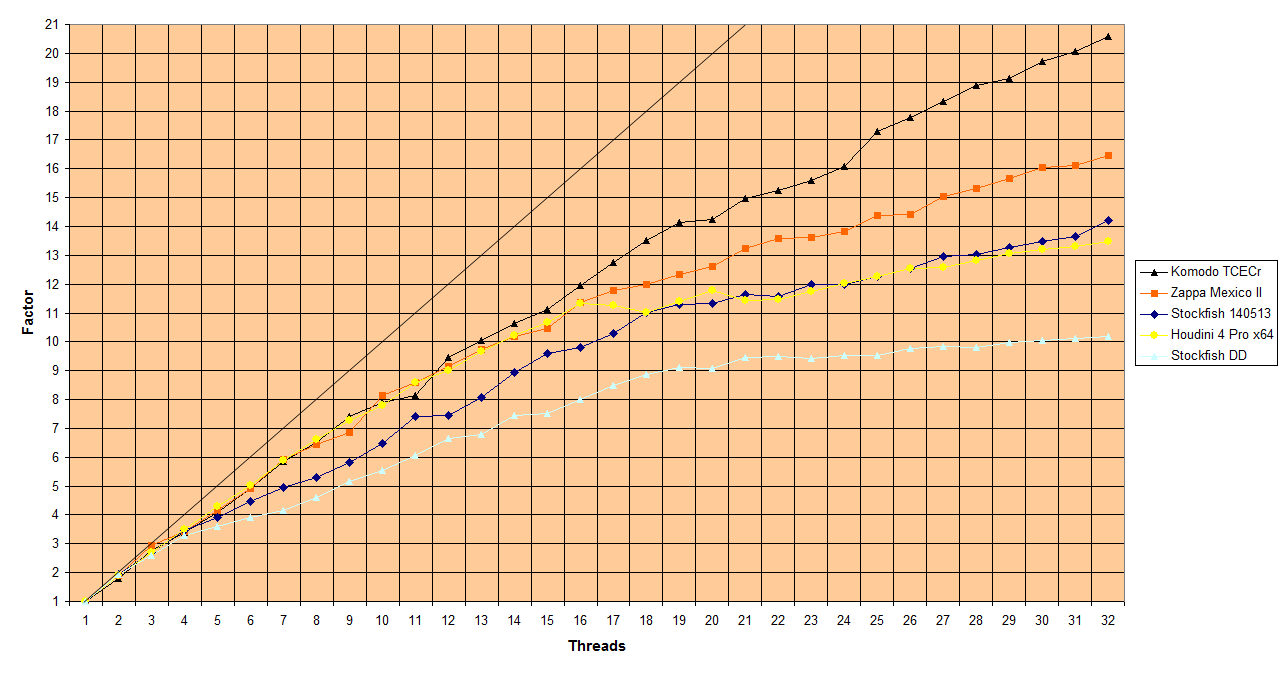
Wenn ich mir die Tabelle so ansehe, dann frage ich mich ob es nicht möglich wäre, dass das Stockfish Team zuerst SMP bei 2 Threads auf 1,99 tunt und erst dann bei 3 Threads auf 2,98 tunen usw. Dadurch lässt sich die höhere Anzahl an Threads besser und vor allem leichter SMP tunen.







 CSS-Shop
CSS-Shop