
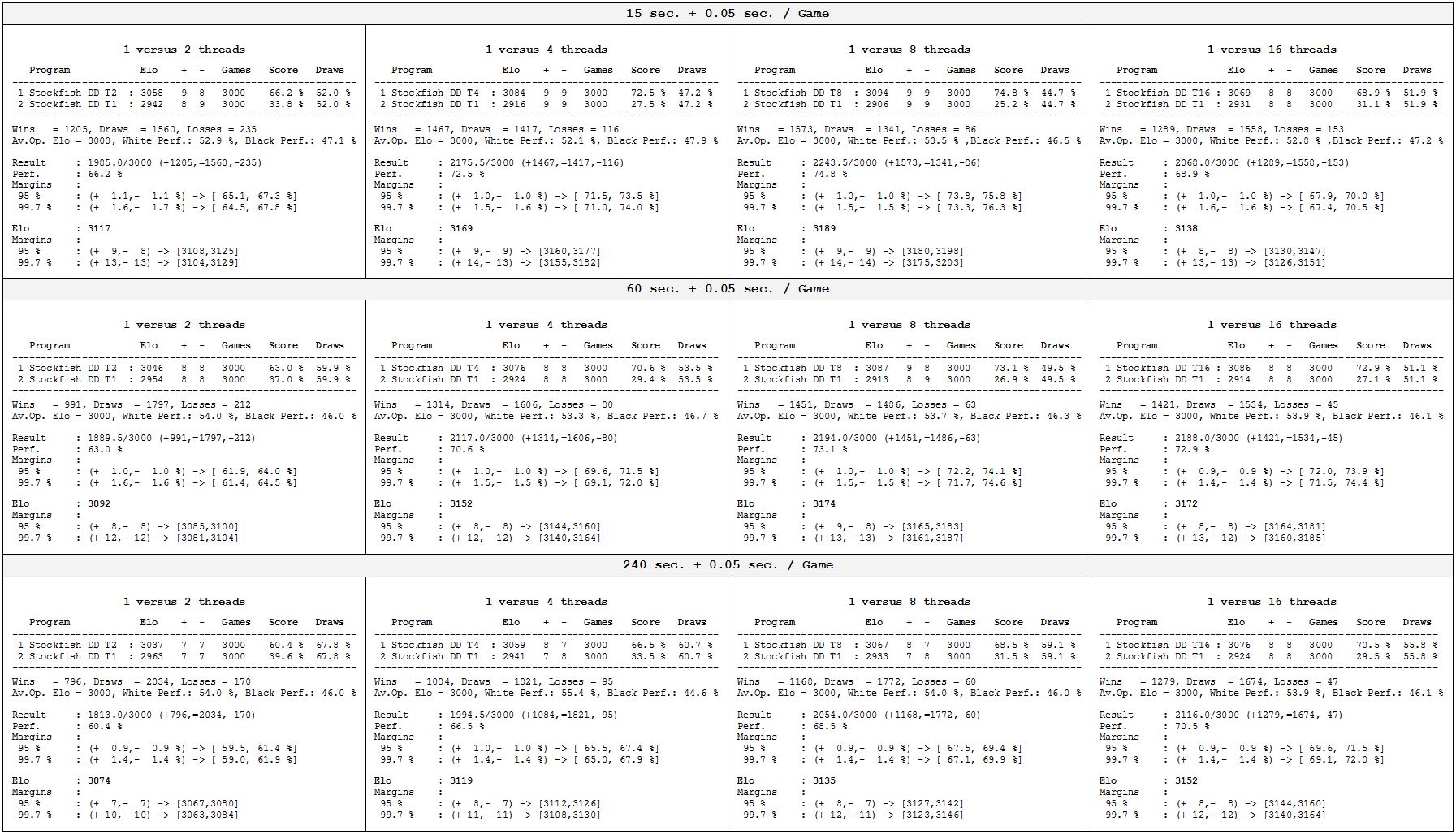
CPU: Dual AMD Opteron 6376 (2x 16 Kerne)
OS: Windows 7 Professional 64-Bit
Tool: Cutechess-Cli
Engine: Stockfish DD 64 SSE4.2
Hash-Table: 128 MB
Eröffnungen: fq1500.pgn - 1500 unterschiedliche Eröffnungsstellungen mit wechselnden Farben (insgesamt 3000 Partien)
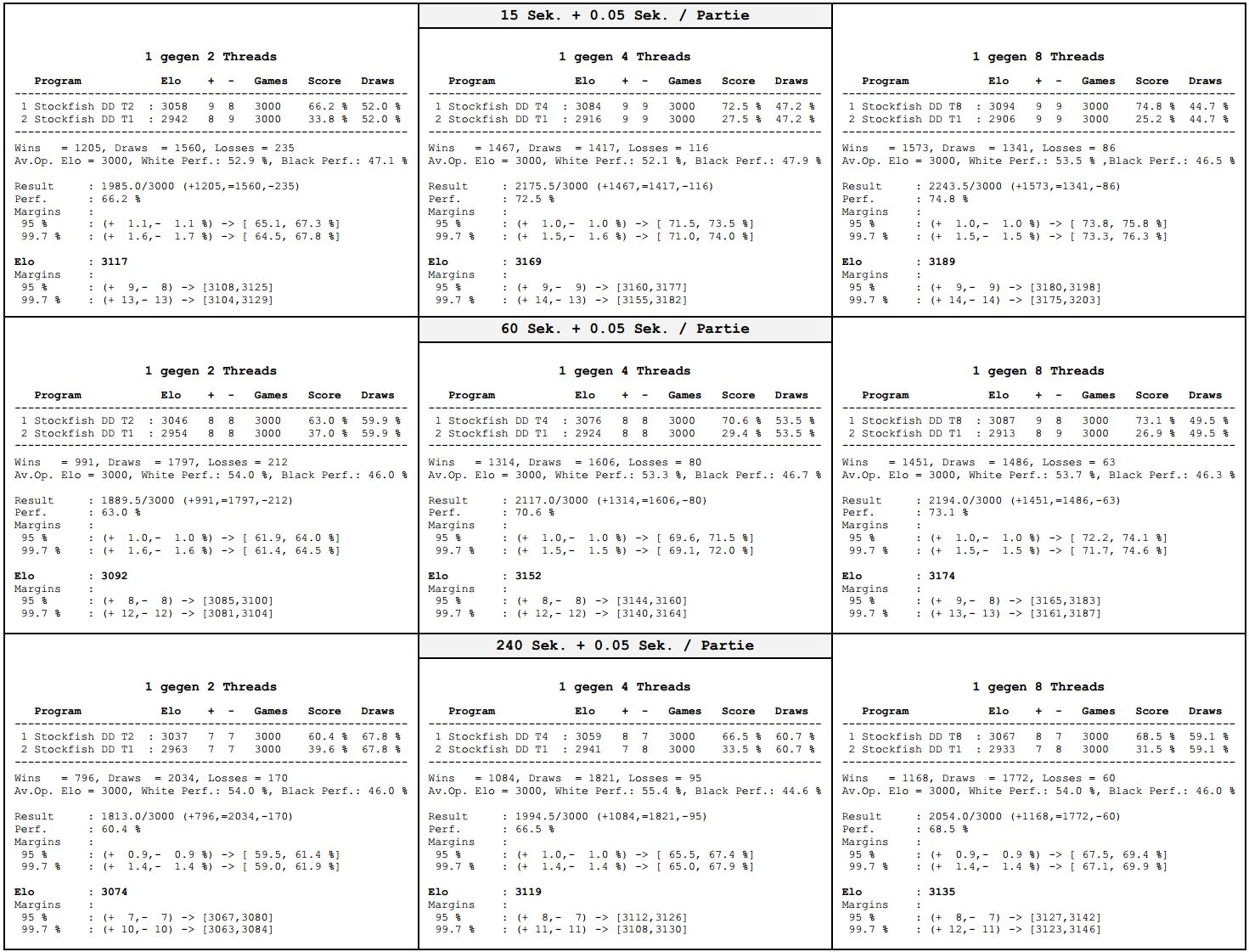
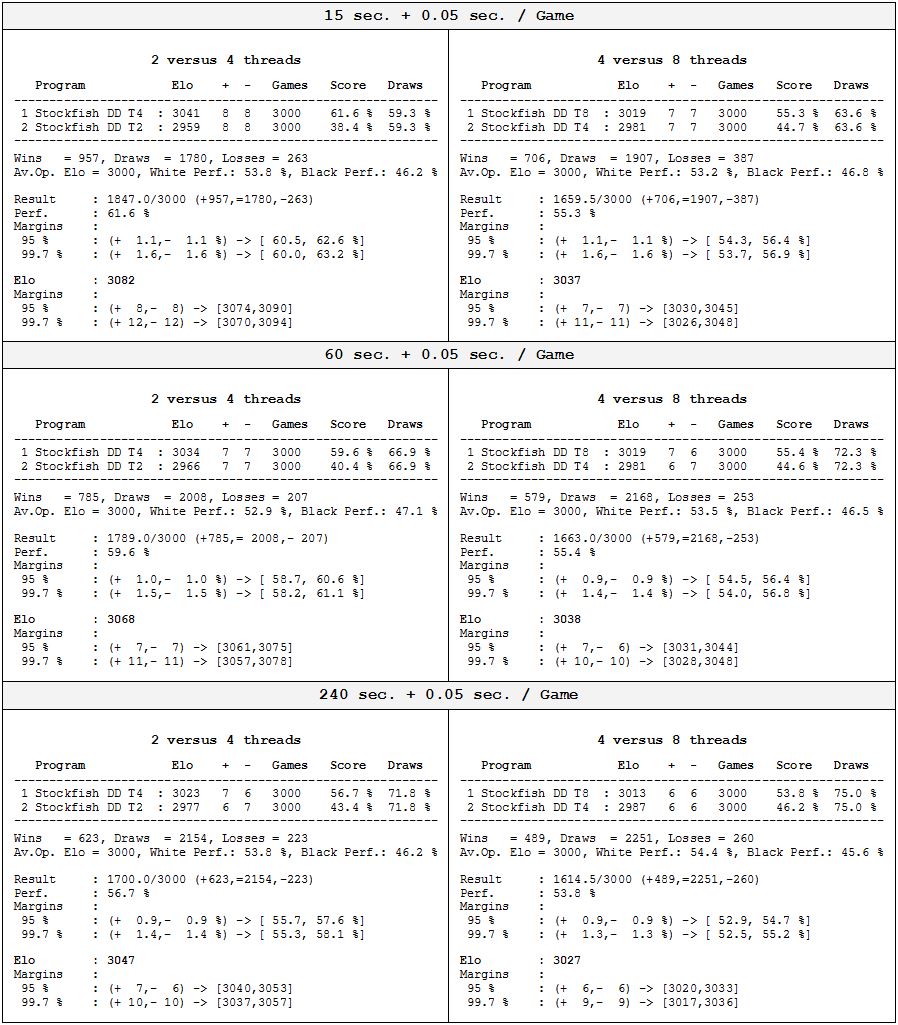
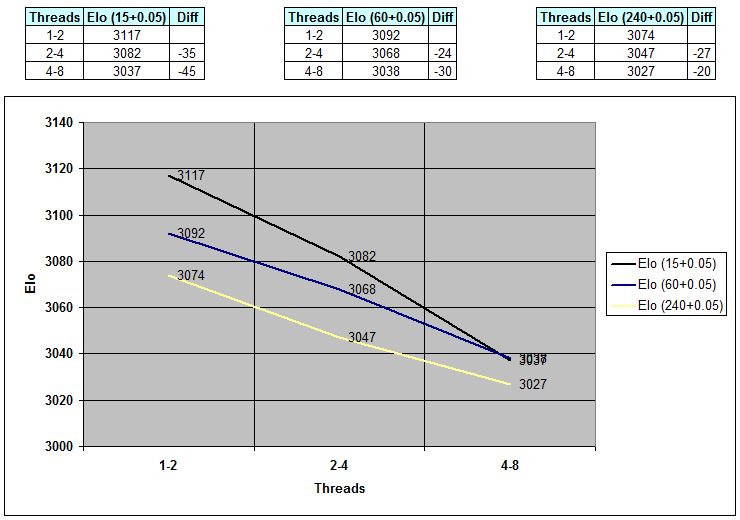
Bedenkzeiten: 15+0.05, 60+0.05 und 240+0.05 Sekunden pro Partie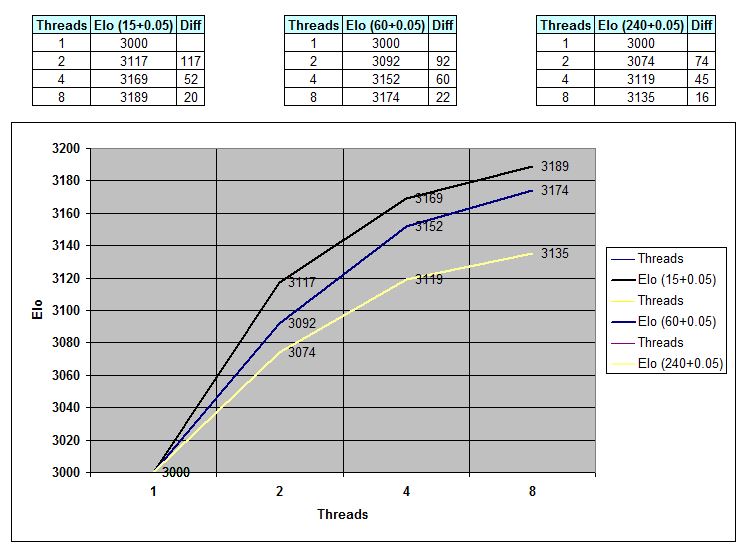


 By ?
Date 2014-03-17 21:11
)
By Ingo B.
Date 2014-04-03 12:52
By ?
Date 2014-03-17 21:11
)
By Ingo B.
Date 2014-04-03 12:52

 By Robert Bauer
Date 2014-04-04 09:01
By Robert Bauer
Date 2014-04-04 09:01
 By Robert Bauer
Date 2014-04-07 12:56
By Robert Bauer
Date 2014-04-07 12:56

1 = 2,78 / 1336
2 = 5,48 / 2628
4 = 10,83 / 5198
8 = 18,44 / 8850
16 = 22,77 / 10931 Integer Test CPU-Mark
1 = 1724 1 = 980
2 = 3447 2 = 1886
4 = 6894 4 = 3496
8 = 13791 8 = 6086
16 = 27591 16 = 9040
32 = 54799 32 = 10226
By Thomas Plaschke
Date 2014-04-07 14:14
/*
************************************************************
* *
* If this is an SMP search, and we have idle processors, *
* now is the time to get them involved. We have now *
* satisfied the "young brothers wait" condition since we *
* have searched one move. All that is left is to check *
* the size of the tree we have searched so far, so that *
* we do not split too near the tips and drive up the *
* overhead unacceptably. This has the additional effect *
* that we might split after 2-3 moves have been searched *
* which might sound like an issue, but the overhead is *
* not so critical if we are more certain that we need to *
* actually search every move. The more moves we have *
* searched, the greater the probability that we are *
* going to search them all. *
* *
************************************************************
*/
By Thomas Plaschke
Date 2014-04-07 16:50

 By Thomas Plaschke
Date 2014-04-07 18:33
By Thomas Plaschke
Date 2014-04-07 18:33
Powered by mwForum 2.29.3 © 1999-2014 Markus Wichitill


 CSS-Shop
CSS-Shop