


 ), was aber die Reihung weiter unten angeht, wird's schon nach dem 3. Platz immer weniger klar, es wird immer mehr drauf ankommen, wer mitspielt (z.B auch an Branches und Settings und Netzen) und so weit kommst du ja mit den halbwegs ans game playing angepassten Stellungstests auch locker.
), was aber die Reihung weiter unten angeht, wird's schon nach dem 3. Platz immer weniger klar, es wird immer mehr drauf ankommen, wer mitspielt (z.B auch an Branches und Settings und Netzen) und so weit kommst du ja mit den halbwegs ans game playing angepassten Stellungstests auch locker.
 By Chess Player
Date 2023-03-01 11:27
Edited 2023-03-01 11:30
By Chess Player
Date 2023-03-01 11:27
Edited 2023-03-01 11:30


Stockfish_230202 102 367
lc0 30dev 102 033
Dragon_3.2 101 311
Berserk_11.1 100 135
Koivisto_9 99 028
Ethereal_14 98 660
RubiChess_221203 98 584
Igel_3.4 98 103
Seer_2.6 97 872
Rebel_16.2 97 652
Revenge_3 97 222
Wasp6.5 94 489
Arasan 88 150Stockfish_16 102 380
lc0 30dev 102 033
Dragon_3.2 101 311
Berserk_11.1 100 135
CSTal2NNUE_Elo 99 307
Koivisto_9 99 028
Ethereal_14 98 660
RubiChess_221203 98 584
Igel_3.4 98 103
Seer_2.6 97 872
Rebel_16.2 97 652
Revenge_3 97 222
Wasp6.5 94 489
Arasan 88 150lc0 31/3905000 102 921
Stockfish_16 102 380
Dragon_3.2 101 311
Berserk_11.1 100 135
CSTal2NNUE_Elo 99 307
Koivisto_9 99 028
Ethereal_14 98 660
RubiChess_221203 98 584
Igel_3.4 98 103
Seer_2.6 97 872
Rebel_16.2 97 652
Revenge_3 97 222
Wasp6.5 94 489
Arasan 88 150
lc0 31/3905000 102 921
Stockfish_16 102 380
Dragon_3.2 101 311
Berserk_11.1 100 135
Koivisto_9.2 99 490
CSTal2NNUE_Elo 99 307
Ethereal_14 98 660
RubiChess_221203 98 584
Igel_3.4 98 103
Seer_2.6 97 872
Rebel_16.2 97 652
Revenge_3 97 222
Wasp6.5 94 489
Arasan 88 150Stockfish_16 106 932
Dragon_3.2 106 134
lc0_400000 106 122
Berserk_11.1 104 863
Koivisto_9.11 104 604
CSTal2_elo 104 370
RubiChess_0410 104 128
Ethereal_14 103 769
Rebel_16.2 103 187
Igel_3.5 102 880
Seer_2.6 102 238
Revenge_3.0 101 769Stockfish_230811 103.062
lc0 31/3905000 102.921
Dragon_3.2 101.311
Berserk_11.1 100.135
Koivisto_9.2 99.490
CSTal2NNUE_Elo 99.307
Ethereal_14 98.660
RubiChess_221203 98.584
Igel_3.4 98.103
Seer_2.6 97.872
Rebel_16.2 97.652
Revenge_3 97.222
Wasp6.5 94.489
Arasan 88.150Stockfish_230811 103.062
lc0 31/3905000 102.921
Dragon_3.2 101.311
Berserk_11.1 100.135
Koivisto_9.2 99.490
CSTal2NNUE_Elo 99.307
RubiChess_230918 99.008
Ethereal_14 98.660
Igel_3.4 98.103
Seer_2.6 97.872
Rebel_16.2 97.652
Revenge_3 97.222
Wasp6.5 94.489
Arasan 88.150Stockfish_230811 103.062
lc0 31/3905000 102.921
Dragon_3.2 101.311
Berserk_230907 101.270
Koivisto_9.2 99.490
CSTal2NNUE_Elo 99.307
RubiChess_230918 99.008
Ethereal_14 98.660
Igel_3.4 98.103
Seer_2.6 97.872
Rebel_16.2 97.652
Revenge_3 97.222
Wasp6.5 94.489
Arasan 88.150File name : 999.epd
Total test items : 999
Test for : best moves
Total engines : 2
Timer : movetime: 0.5
Expand ply : 1000
Elapsed : 25:02
Laps : 1
Total tests : 1998
Total corrects : 1676 (83%)
Ave correct elapse : 320 ms
Status : completed
Correct/Total:
Berserk 20230907: 845/999
Berserk 20230818: 831/999
Wins = 46
Draws = 922
Losses = 31
Av.Op. Elo = 3500
Result : 507.0/999 (+46,=922,-31)
Perf. : 50.8 %
Margins :
68 % : (+ 0.4,- 0.4 %) -> [ 50.3, 51.2 %]
95 % : (+ 0.9,- 0.8 %) -> [ 49.9, 51.6 %]
99.7 % : (+ 1.3,- 1.3 %) -> [ 49.5, 52.1 %]
Elo : 3505
Margins :
68 % : (+ 3,- 3) -> [3502,3508]
95 % : (+ 6,- 6) -> [3499,3511]
99.7 % : (+ 9,- 9) -> [3496,3514]
Stockfish_230811 103.062
lc0 31/3905000 102.921
Dragon_3.2 101.311
Berserk_230907 101.270
Koivisto_9.2 99.490
CSTal2NNUE_Elo 99.307
Clover_6.0 99.010
RubiChess_230918 99.008
Rebel_EAS 98.798
Ethereal_14 98.660
Igel_3.4 98.103
Seer_2.6 97.872
Revenge_3 97.222
Wasp6.5 94.489
Arasan 88.150
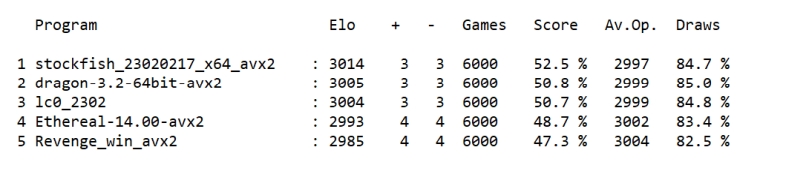
Program Elo +/- Matches Score Av.Op. S.Pos. MST1 MST2 RIndex
1 Stockfishdev-20230903 : 3511 1 7959 51.7 % 3499 722/779 1.0s 1.0s 0.98
2 Lc0v0.31.0-dag+git.f4d40b-5230M : 3507 1 7877 51.1 % 3499 699/779 1.0s 1.0s 0.99
3 Dragon3.2byKomodoChess64 : 3505 1 7788 50.8 % 3500 698/779 1.0s 1.0s 0.97
4 Berserk20230907 : 3503 1 7714 50.4 % 3500 683/779 1.0s 1.0s 0.97
5 Clover6.0 : 3500 1 7675 50.1 % 3500 674/779 1.0s 1.0s 0.98
6 Chess-System-Tal-2.00-v21-E1162-EAS.opt : 3499 1 7661 49.9 % 3500 673/779 1.0s 1.0s 0.96
7 RubiChess20230410 : 3499 1 7649 49.8 % 3500 666/779 1.0s 1.0s 0.97
8 Revenge3.0 : 3498 1 7650 49.7 % 3500 662/779 1.0s 1.0s 0.97
9 Ethereal14.00(NNUE) : 3498 1 7619 49.6 % 3500 660/779 1.0s 1.0s 0.97
10 Chess-System-Tal-2.00(RebelEAS) : 3497 1 7613 49.5 % 3500 658/779 1.0s 1.0s 0.96
11 Arasan24.0 : 3496 1 7639 49.3 % 3500 652/779 1.0s 1.0s 0.97
12 Wasp6.50 : 3487 2 7528 47.9 % 3501 613/779 1.0s 1.0s 0.96
MST1 : Mean solution time (solved positions only)
MST2 : Mean solution time (solved and unsolved positions)
RIndex: Score according to solution time ranking for each position
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
-------------------------------------------------------------------------------------
0 | - 0 - 0 0 0 - 0 0 - - 0 0 0 0 0 0 0 0 0
20 | 0 - 0 0 0 - - 0 0 0 0 0 0 0 0 0 0 0 0 0
40 | 0 - 0 0 0 0 0 0 0 0 0 0 0 0 - 0 0 0 0 -
60 | 0 0 0 0 0 0 0 0 - 0 0 0 0 0 - 0 - 0 0 0
80 | 0 0 0 0 0 - 0 0 0 - - - 0 0 0 0 0 - 0 0
100 | 0 0 0 0 0 0 0 - 0 0 0 - 0 - 0 0 0 0 - 0
120 | 0 0 - 0 - 0 0 0 - 0 0 0 0 0 0 0 0 0 0 0
140 | 0 - 0 0 - 0 0 0 0 - 0 0 0 0 - 0 0 0 0 0
160 | 0 0 0 0 - 0 0 0 0 - 0 0 - 0 0 0 0 0 0 0
180 | 0 0 0 0 0 0 0 - 0 0 0 0 0 - - 0 - - 0 -
200 | - 0 0 0 0 0 0 0 0 0 - 0 0 - 0 0 - 0 0 0
220 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 - - 0
240 | 0 0 0 0 0 0 0 - 0 0 0 0 0 - 0 0 0 0 0 -
260 | 0 0 - 0 0 0 0 0 0 0 - 0 0 0 - 0 0 0 0 -
280 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 - 0 0 0 0 0
300 | - 0 0 0 - - 0 - 0 0 0 0 0 0 0 0 0 - 0 0
320 | 0 - 0 0 0 0 - - 0 0 0 0 0 0 0 0 0 0 0 0
340 | 0 0 0 - 0 0 0 0 0 0 0 - 0 0 0 0 0 - 0 -
360 | 0 0 - 0 - 0 - 0 - 0 0 0 0 0 0 0 0 0 0 0
380 | 0 - 0 - 0 0 0 - 0 0 0 0 - 0 0 0 0 - 0 0
400 | 0 - - 0 0 - 0 0 0 - 0 0 0 - 0 0 0 - 0 0
420 | 0 0 0 - 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 -
440 | - 0 0 0 0 - 0 0 0 0 0 0 - 0 - 0 0 - 0 0
460 | 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0 0 0 0 0
480 | - - 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0 0 0 0
500 | 0 0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0 0 -
520 | - 0 0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0 0
540 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 - 0 0 0 0 0
560 | - - - 0 0 - 0 0 0 0 0 0 0 0 0 0 0 - 0 -
580 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
600 | - - 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 - 0
620 | 0 0 0 - - 0 0 0 0 - 0 0 - 0 0 0 0 0 0 0
640 | 0 0 - 0 0 0 - 0 0 0 0 - 0 - 0 0 0 0 0 0
660 | 0 0 0 0 - 0 0 0 - 0 0 0 - 0 - 0 0 0 0 0
680 | 0 0 0 0 0 0 0 0 0 0 0 0 0 - - - 0 0 0 0
700 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
720 | 0 0 0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0 0
740 | 0 0 0 0 0 0 0 0 0 0 0 - 0 0 0 - - 0 0 -
760 | - 0 - - 0 0 0 0 0 0 0 0 - 0 0 0 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
-------------------------------------------------------------------------------------
0 | 0 0 0 0 0 0 - 0 0 - 0 0 0 0 0 0 - - 0 0
20 | 0 - 0 0 0 - 0 0 0 0 0 0 0 0 0 0 0 0 0 0
40 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 - 0 0 0 0 -
60 | 0 - 0 0 0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0
80 | 0 0 0 0 0 0 0 0 0 - - - 0 0 0 0 0 - - 0
100 | 0 0 0 0 0 0 0 - 0 0 0 - 0 0 0 0 0 0 - 0
120 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
140 | 0 - 0 0 0 0 0 0 0 0 0 0 0 0 - 0 0 0 0 0
160 | 0 0 0 0 - 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
180 | 0 0 0 - 0 0 0 - 0 0 0 0 0 0 - - - 0 0 0
200 | 0 0 - - 0 0 0 0 0 0 - 0 0 0 0 0 0 - - 0
220 | 0 0 0 0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0
240 | 0 0 0 0 0 0 0 - 0 0 0 0 0 - 0 0 0 0 0 -
260 | 0 0 - 0 0 - 0 0 0 0 0 0 0 0 0 0 0 0 0 -
280 | 0 0 0 0 0 0 0 0 0 0 0 0 0 - - 0 0 0 0 0
300 | - 0 0 0 0 - 0 - 0 0 - 0 0 0 0 0 0 - 0 0
320 | 0 - 0 0 0 - - - 0 0 0 0 0 0 0 0 0 0 0 0
340 | 0 0 0 0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 -
360 | - 0 - 0 - 0 0 0 0 0 - 0 0 0 0 0 0 0 0 0
380 | 0 0 0 - 0 0 0 - - 0 0 - - 0 0 - 0 0 0 0
400 | 0 0 0 0 0 - 0 0 0 0 0 0 - - 0 0 0 0 0 0
420 | 0 0 0 - 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0 -
440 | - 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0 0 0 0
460 | 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0 0 0 0 0
480 | - - 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
500 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
520 | 0 - 0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 - 0 0
540 | 0 0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0 0 0
560 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 -
580 | 0 0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0 0 0
600 | 0 - 0 0 0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0
620 | 0 0 0 - - 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
640 | 0 0 0 0 0 0 0 0 0 0 0 - 0 0 0 0 0 0 0 0
660 | 0 0 0 0 - 0 0 0 - 0 0 0 0 0 - 0 - 0 0 0
680 | 0 0 0 0 0 0 0 0 0 0 0 0 - 0 0 - 0 0 0 -
700 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
720 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 - 0 0 0
740 | 0 - 0 0 0 0 0 0 0 0 0 0 0 0 0 - - 0 0 -
760 | 0 0 - - 0 0 0 0 0 0 0 0 - 0 0 0 0Wins = 63
Draws = 665
Losses = 49
Av.Op. Elo = 3300
Result : 395.5/777 (+63,=665,-49)
Perf. : 50.9 %
Margins :
68 % : (+ 0.7,- 0.7 %) -> [ 50.2, 51.6 %]
95 % : (+ 1.3,- 1.3 %) -> [ 49.6, 52.2 %]
99.7 % : (+ 2.0,- 2.0 %) -> [ 48.9, 52.9 %]
Elo : 3306
Margins :
68 % : (+ 5,- 5) -> [3302,3311]
95 % : (+ 9,- 9) -> [3297,3316]
99.7 % : (+ 14,- 14) -> [3292,3320]
EPD : 777
Time : ms
Max Total Time Hash
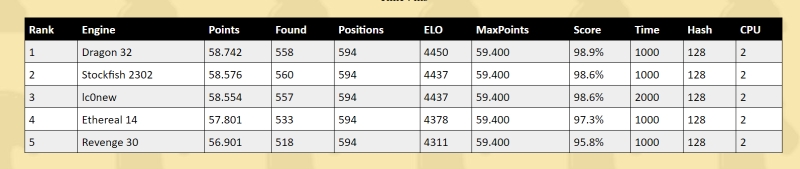
Engine Score Found Pos ELO Score Rate ms Mb Cpu
1 SF230903 10457 730 777 4225 11138 93.9% 500 4 1
2 lc0v31.0-5230M 10096 718 777 4077 11138 90.6% 500 2 2
3 Berserk230907 10016 706 777 4045 11138 89.9% 500 4 1
4 CSTal2Elo 9861 700 777 3982 11138 88.5% 500 4 1
5 Ethereal14 9724 693 777 3928 11138 87.3% 500 4 1
6 RubiChess2230918 9722 691 777 3928 11138 87.3% 500 4 1
7 Wasp6.50 9374 663 777 3789 11138 84.2% 500 4 1
8 Texel1.10 9010 645 777 3640 11138 80.9% 500 4 1
9 Texel1.09 8627 622 777 3487 11138 77.5% 500 4 1
Created with MEA
by
Ferdinand
Mosca
Powered by mwForum 2.29.3 © 1999-2014 Markus Wichitill


 CSS-Shop
CSS-Shop